


Cold Take on Open AI’s o1


I've now had some time to play around with the latest LLM from OpenAI called o1, and think about its implications.
Firstly, o1 is part of the "Strawberry" AI reasoning project and is designed to solve complex problems by breaking them down into their component parts and handling them step by step using Chain of Thought (CoT) reasoning, built into the model itself rather than simply using it in the prompt.
These aren't hot takes, but rather cold takes, a more measured perspective on where I think things are headed.

Open-Source o1 Models
I believe the open source versions of o1 will be the real game changers. So await releases from Meta, Mistral, Falcon etc.
Open source models offer several advantages over proprietary ones. Open-source models are constrained in their outputs, smaller, faster, and cheaper. They are fully configurable, allowing for better customisation to specific tasks and infrastructure. They can be run locally, reducing network latency and enabling faster processing times.
Looking back over the past 12 months its clear open-source has caught up with the proprietary models and the gap in performance will shrink over time.
CoT throws open a new capability for proprietary models but my guess is that the open-source versions will follow up very quickly. Most of the ‘Strawberry’ research and ideas have been out in the open for a while and things have been cooking in AI research labs. The clock is ticking..
The Economics of Inference-heavy LLMs
The economics of inference-heavy models like o1 are complex. The GPT models so far have been focused on cost at training, with light inference time processing. o1 has a higher component of processing at inference vs training.

While the cost of training LLMs is significant, the cost of inference can far exceed training costs when deploying these models at scale. For instance, OpenAI's ChatGPT reportedly generates around 100 billion tokens per day, leading to inference costs that exceed the training costs on a weekly basis. This highlights the importance of considering both training and inference costs in the overall economic analysis of AI models.
The tradeoff between training and inference compute is a critical factor in understanding the economics of AI models. Techniques such as pruning, resampling, and chain of thought can be used to reduce inference costs, but these methods often come at the expense of model performance. Also, the cost of running a single inference is much smaller than the cost of training, but the aggregated cost of inference over the lifetime of a model can greatly exceed the cost of training due to the large number of inferences performed.
While these models have the potential to revolutionise various applications, their inference-heavy nature could make the cost of deploying these models at scale prohibitively expensive.
o1 vs. A Human Graduate Student

I've done some analysis on the cost of AI vs. human graduate students, and the numbers are eye-opening:
Average cost of an O1 "grad student": ~$20 per month (reading, analyzing, and writing about 6-7 academic papers per day)
Average cost of a human grad student: ~$2500 per month
This means we could potentially have 120 AI "grad students" for the price of one human student.
I’m not saying replace all human graduate, but this does suggest that scientific advancement could accelerate dramatically with profound delta’s in the cost of intelligence.
AI can already assist in literature reviews, summarising vast quantities of literature and highlighting areas for future investigation. This not only saves time but also enhances the reliability and reproducibility of research.
In any case, we clearly have a new paradigm emerging of LLMs disrupting academic research in profound ways.
Check out Sakana AI Scientist
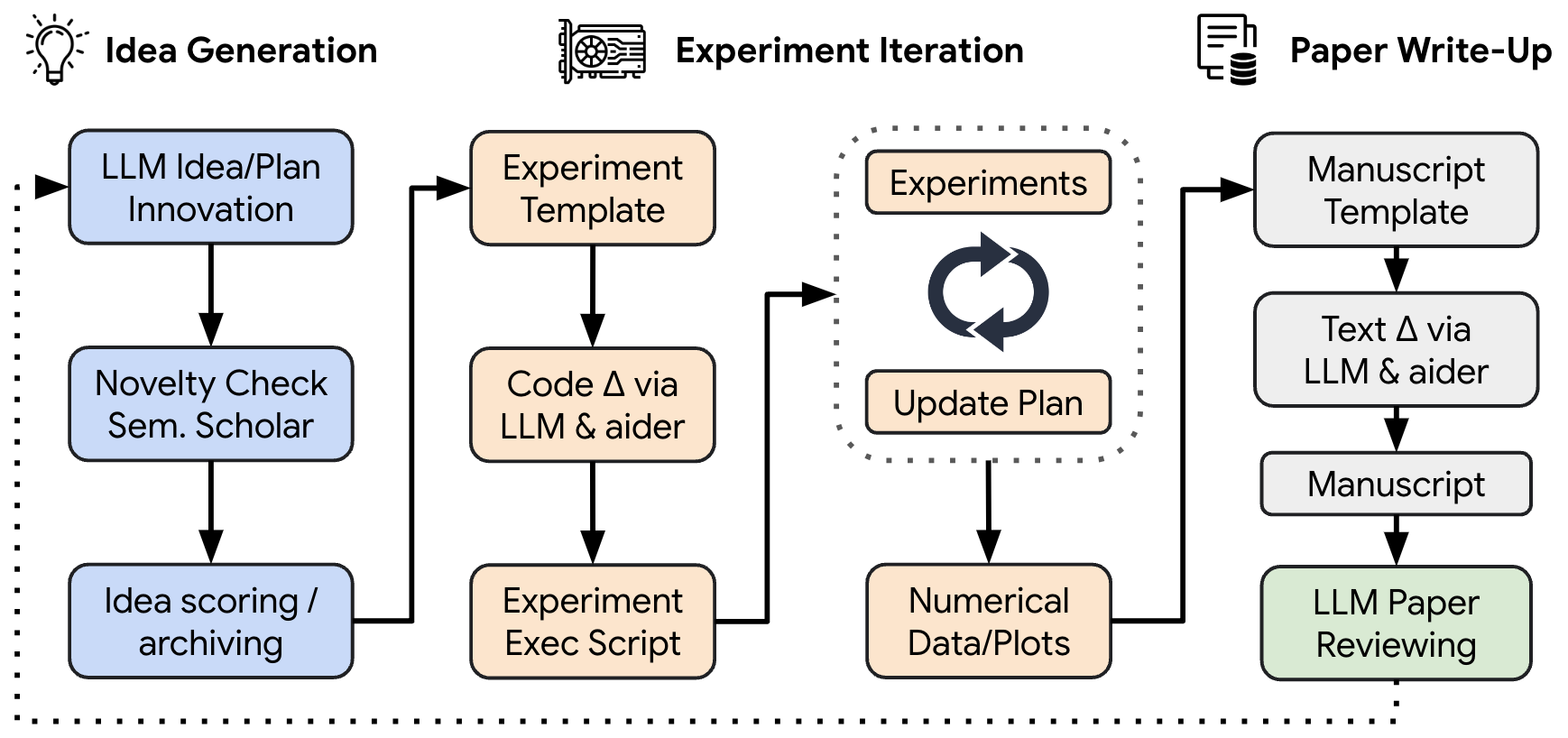
Specialised Models
We're seeing a trend towards specialised best-in-class models for different tasks like writing (Claude 3.5), coding (Claude 3.5), reasoning (o1), searching (Perplexity Sonar), unbiased analysis (Llama 3.1), video generation (Runway Gen3 Alpha), audio generation (Google MusicLM) and image generation (DALLE-3, Midjourney).
Instead of one model to rule them all, we'll likely use a subset of models tailored to specific tasks.
Instead of one model to rule them all, we'll likely use a subset of models tailored to specific tasks.
While there will still be a place for general-purpose AI models, the market seems to be driving towards an ecosystem of specialised AI providers. This diversification benefits innovation and competition, reducing the risk of monopolies and encouraging open source models to keep pushing in specific domains.
Blended AI Platforms
I strongly believe there's a trillion-dollar opportunity in creating an intuitive, easy to use platform that uses multiple models and completes a specific task using agents talking to specialised models (proprietary and open source) based on the prompt i.e. a ‘Blended AI platform’.
I've experienced this firsthand when recently building a deal sourcing tool for VCs based on LLMs. Breaking down tasks and using different models for each sub-task yielded better results than using a single model for all tasks.
What exists currently is prompts being run on specific models i.e. Perplexity does this very well using an easy to understand interface. However each prompt is run with a singular model pre-specified by the user. One can also rewrite the output using a different model. Perplexity also is one of the few GenAI providers that is providing a true CoT, agentic platform that breaks down each task into sub-tasks and then runs them separately, although all the tasks are run on a singular model. This is very similar to how o1 works.
Now imagine, Perplexity running each of their agentic sub-tasks on separate models, choosing different models for different tasks. This is a complex problem to solve as the costs per task will be varied, linked to costs of the model and number of tokens being passed on.
I think this is the future of GenAI.
The Implications of o1 for Enterprises
The impact of CoT models, like OpenAI’s o1, in the enterprise is still unclear. o1 has potential in corporate R&D labs at pharma for example, and horizontal areas like supply chain management where agentic CoT reasoning could unlock new optimisations for supply chain.
The truth is that like any other new fangled technology it will take time for companies to evaluate and find the best use cases. Most companies have yet to understand GPT-3, let alone GenAI and its implications.
However, I can't stress this enough - any enterprise ignoring GenAI today risks becoming irrelevant in the next 3-5 years.
Any enterprise ignoring GenAI today risks becoming irrelevant in the next 3-5 years
The adoption of GenAI in enterprises is a complex process. It requires not only technical know-how but also a thorough understanding of the business, processes and its needs. This includes identifying the right use cases, developing appropriate workflows, and addressing regulatory concerns.
The integration of GenAI into existing systems and processes is a significant challenge and requires careful planning and execution to ensure minimal disruption to business operations.
While the plumbing and engineering around GenAI will get better over time, one needs to begin that process now. Otherwise, the learning curve will get steeper as the technology progresses.
Getting on the ladder now will make things easier for organisations that have already solved the people and process issues, which in my view are the most important, and are the hardest to solve. Once you have solved these, the technology adoption becomes much simpler.
What are your thoughts on o1 and its potential impact?
Let me know in the comments below!