
Issue #2: The Intelligence Explosion and Its Impact On The Enterprise AI Landscape
Disrupting Proprietary AI, Tech Stacks, Cloud Compute and Data Pipelines


In a recent Dwarkesh Patel podcast spanning a mind-boggling 7 hours across two episodes, Carl Shulman provided a multidimensional view of the landscape, from its extraordinary potential to existential risks.
Carl works at the Future of Humanity Institute at Oxford University and explores a range of topics primarily centred around the long-term impacts of AI and biotechnology. His work intersects with broader themes of future forecasting, existential risks, and effective altruism, aiming to understand and mitigate potential challenges humanity might face due to advancements in these fields.
Dwarkesh is an excellent podcaster and large-scale thinker, and has been recently producing some real bangers that dive into topics like never before.
Their wide-ranging chat explored topics including recursive self-improvement cycles, forecasting progress, alignment challenges, takeover scenarios, deception detection, global coordination, and envisioning long-term futures.
This multifaceted conversation illuminates the potential of AI alongside the existential risks if its development accelerates beyond our ability to ensure beneficial outcomes.
If one needed any more proof, its crystal clear that we are at the start of an Intelligence Explosion and that large language models (LLMs) have ignited it.
Companies must rethink strategy across dimensions from proprietary IP to data curation to cloud differentiation to promote responsible outcomes.
All enterprises have a stake in the issues explored, whether building AI directly or operating in an industry AI will transform. Without collective coordination for safe, ethical advancement, no organisation can address risks like misalignment in isolation.
In general, we need a measured approach to safety and governance for these LLMs as going too far will produce worse possibilities.
While the ethical, safety and governance implications are far too vast for covering in one newsletter, we’ll start by focusing first on what this means for the existing AI/ML landscape.
In this issue of "The Uncharted Algorithm," we will explore critical transformations in the following areas more focused on the status quo of the AI/ML industry and how one should think about LLMs in that context:
Proprietary AI Models: As the age of proprietary models wanes, the focus will shift towards leveraging and fine-tuning general LLMs.
Data Pipelines: As the data landscape changes, we examine how pipelines must evolve from merely being large to being intelligent and agile.
AI Tech Stack: We'll look at the need for a radical overhaul of your technology stack to remain competitive in this LLM-dominated landscape.
Cloud Providers: In a world where LLMs are increasingly doing the heavy lifting, cloud providers need to reevaluate their value propositions.
Proprietary AI Models

The existing AI landscape in the business sector primarily revolves around creating and training proprietary, domain-specific models. This approach demands a substantial investment of resources, both in terms of data collection and data science expertise, to develop, train, and maintain these models.
However, a new wave of AI, characterised by generalised LLMs or Foundational Models like GPT, Claude, LLAMA etc. are reshaping the way enterprises adopt AI technologies.
The emergence of these GenAI models suggests a shift from building proprietary models to leveraging and fine-tuning already existing, well-rounded foundational models.
The concept of Retrieval Augmented Generation (RAG) plays a crucial role here, enhancing the foundational model's ability to provide domain-specific responses and reduce hallucinations.
Today most of the LLMs in the enterprise are powering chatbots, particularly in customer service domains. However, the potential applications are vast, ranging from writing code, conducting sentiment analysis, data analytics, language translation, marketing and advertising, workflow automation, engaging in voice conversations and many more.
With this shift, the marketplace for proprietary AI models could face obsolescence. We're beginning to see this with multimodal LLMs, which are diminishing the reliance on traditional computer vision models.

The foundational model approach simplifies operations, reduces costs, and requires less specialised expertise, making it an attractive proposition for enterprises.
Here's a look at how this shift impacts different facets of the AI enterprise ecosystem:
Implications for AI Marketplaces and Data Firms: Existing marketplaces and firms specialising in domain-specific datasets might find their business models challenged. Customers may gravitate towards providers that assist in customising foundational models rather than building new ones from scratch. This transition could potentially disrupt the current AI model marketplaces, favouring a new breed of providers adept in fine-tuning generalised models.
The Multimodal LLM Frontier: Multimodal LLMs, capable of handling various types of data, are at the forefront of this transition, phasing out traditional computer vision models. This capability represents a significant leap towards a more unified, cost-effective AI model that can tackle diverse tasks with a single model.
Potential Hurdles: The GenAI approach is not without its challenges. Fine-tuned models might not yet match the performance of bespoke models in highly specialised domains. Moreover, there's the inherited bias issue and the requirement for specific data for fine-tuning, which need addressing.
While challenges like performance matching in highly specialised domains and inherited bias issues are pertinent, the trajectory towards a more unified AI model through multimodal LLMs is unequivocally clear.
This shift not only redefines the contours of AI marketplaces but also sets the stage for an intelligent, agile, and efficient data pipeline paradigm that dovetails seamlessly with the evolving AI landscape.
Data Pipelines

The advent of Foundational LLMs heralds a paradigm shift in how data pipelines are conceived and implemented.
By simplifying code generation through text prompts, LLMs open the doors for non-technical users to independently construct AI data pipelines.
This is a stark departure from the traditional method where the design of pipeline workflows often necessitated a solid grounding in programming languages, thereby creating a barrier for non-engineers.
In the operational sphere, LLMs such as ChatGPT are garnering traction across various facets of data engineering including data ingestion, data transformation, DataOps, and orchestration.
These models facilitate the generation of complex code from simple text prompts, which could empower even non-technical users to build AI data pipelines independently.
This represents a shift from the conventional approach where the design of pipeline workflows often demands a solid grounding in programming languages, thus posing a challenge for non-engineers.
Assisting Data Engineering: Many data engineers are turning to LLMs to assist with data ingestion, transformation, DataOps, and orchestration. The versatility of LLMs like ChatGPT comes into play across these segments, making tasks more manageable and less time-consuming for data engineers.
Documentation: One of the notable utilities of LLMs like ChatGPT in data engineering is in documentation. They can help draft documentation that outlines the tasks involved in various segments of data engineering. This capability alleviates the documentation burden from data engineers, which could potentially accelerate the pipeline development process.
Enhanced Productivity: A poll cited by Eckerson Group revealed that a substantial percentage of practitioners are already leveraging LLMs to assist in data engineering. More specifically, over half of the respondents use ChatGPT for documentation, while around 18% use it for designing and building pipelines, showcasing the practical utility and enhanced productivity afforded by LLMs.

Source: Eckerson Group
Learning New Techniques: Besides aiding in documentation and pipeline construction, LLMs also serve as tools for learning new techniques, further showcasing their multifaceted role in data engineering.
Code Troubleshooting and API Calls: ChatGPT can assist data engineers with a range of tasks including troubleshooting code and generating API calls, which are crucial in the data engineering domain.
Data Cleaning and Feature Engineering: In the realm of data analysis, which is a crucial part of data engineering, LLMs assist in data cleaning, feature engineering, and other fundamental stages, making the field more accessible to beginners and domain experts from non-technical backgrounds.
These interventions underscore the role of LLMs in redefining the data engineering landscape, making it more accessible, efficient, and agile.

This transition resonates with the wider movement towards harnessing generalised AI to address domain-centric challenges, as LLMs furnish a flexible, efficient, and accessible framework that will redefine AI data pipelines.
AI Tech Stack
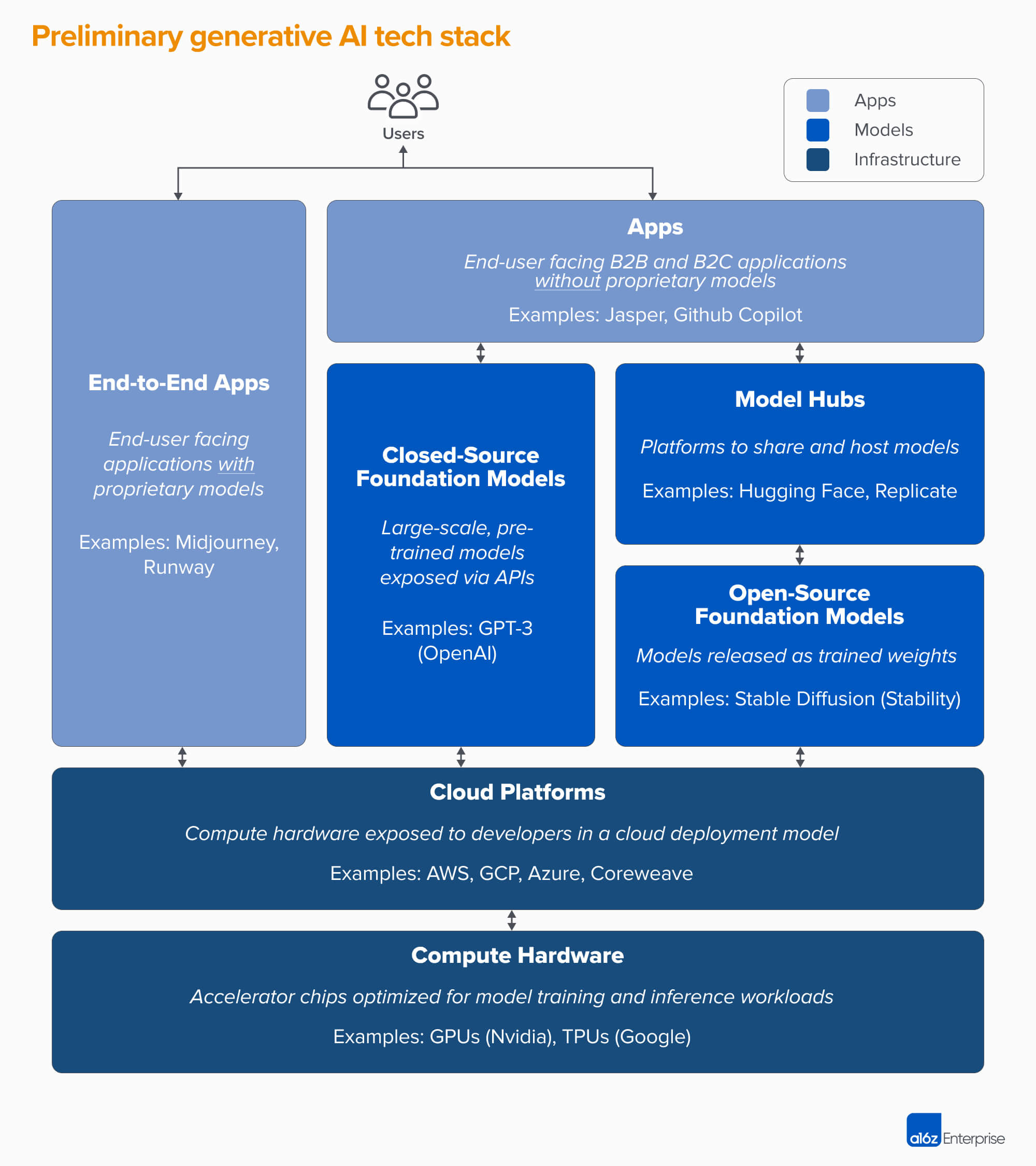
Source: A16Z
Lets talk about what all of this means to the AI tech stack.
There has been talk of new AI tech stack designed to exploit the full potential of LLMs. This new stack veers towards enabling interactions (text-based and other) with systems, contrasting the previous tech stacks focused on building discrete, specialised models.
In early 2023, Andreessen Horowitz (A16Z) published their preliminary version of the GenAI tech stack. I think this still holds up pretty well and is aligned with how I see the reshaping of the AI landscape.
This structure gives a comprehensive overview of the imminent terrain Foundational Models, and a tri-layered approach helps us decode this evolution.
Infrastructure » Models » Apps
In the current AI/ML tech stack, enterprises face a somewhat convoluted process. They need to engage with infrastructure providers for model development and training, often considering investments in dedicated hardware.
This means not just purchasing servers and chips but ensuring a seamless orchestration across every layer, from the foundational infrastructure right up to user-focused applications. It is a meticulous task that requires integration of multiple, often disparate, elements. And yes, there are providers that will build and manage this bespoke for you.
While there are entities that offer all-encompassing solutions, touching every aspect of this tech stack, the advent of Foundational GenAI brings a new dawn.
The prediction is clear: there will be a marked surge in providers who specialise in delivering end-to-end applications. This won't just be generic applications, but a fresh wave of vendors will emerge, focusing on crafting domain-specific applications, all built atop these Foundational Models.
What's particularly intriguing is the diminishing centrality of once-dominant AI/ML frameworks like Keras, Pytorch, and others. These were the linchpins of earlier AI models, but as the paradigm shifts towards larger, more intricate models with recursive self-building features, their significance is waning.
This doesn’t mean they’ll vanish – they’ll be tools in the arsenal of Foundational Model companies. But their frontline status is likely to be eclipsed.
There is going to be a significant redistribution of value within the AI tech stack. Foundational Model companies are poised to be the new juggernauts.
Based on projections by Carl Shulman that were covered in the podcast, the financial dynamics are about to be supercharged. Shulman projects that the current scaling of Foundational Models can easily reach up to $100 billion for model training.
This isn't just a marginal increase but a massive leap, overshadowing investments made in predecessors like GPT-4 by three orders of magnitude!
These Foundational Model giants won't just be repositories of investment; they'll also be the primary sources of return. By rolling out indispensable APIs and crafting tools, they'll become the backbone on which enterprises will innovate.
As per Shulman, if Foundational Model companies are spending $100 billion on a training run, they are likely to see value accrued at least 10x that in the trillions of dollars as these models become the backbone of the global economy.
This is a seismic shift from the prior AI/ML model where infrastructure companies, the hardware and platform providers, were the primary beneficiaries.
The future indicates that while these Infrastructure providers will retain importance, their primary interactions will pivot. They'll primarily liaise with Foundational Model firms, leaving direct dealings with end-users and businesses in the backdrop.
This reshuffling is not just a technological realignment but an economic and strategic one, redefining the very essence of the AI tech ecosystem.
Cloud Providers

The rise of LLMs has forced a re-evaluation of value propositions among AI cloud providers. As mentioned earlier, we are walking into a future where the Foundational Model companies will likely rule.
Here's an exploration of the fast-changing landscape, including a look at the actions of major AI cloud players AWS, Microsoft, and Google:
Current Positioning
Cloud providers see enormous potential in Foundational Models and are racing to partner with or invest in LLM companies to gain exclusive access. This echoes past platform battles like cell phone carriers vying for exclusive rights to hot new phones.
Microsoft made an early and massive $1 billion investment in OpenAI in 2019, securing exclusive Azure access to models like GPT-4 and Dalle. This is paying dividends as Microsoft leverages its OpenAI access to drive Azure adoption.
AWS has taken a more open, neutral approach, partnering with multiple LLM players like Anthropic, Cohere, and AI21 Labs. The aim is to position AWS as the "Swiss Army Knife" of LLMs, reducing friction for developers.
Google Cloud has invested in Anthropic and Cohere and is building up its stable of proprietary models like LaMDA and PaLM. It provides LLM access via its managed ‘Model Garden’ service.
Amazon’s recent $4 billion investment in Anthropic makes things interesting as they call themselves its ‘primary‘ cloud provider. The narrative gets murkier with Google’s earlier $400 million stake in Anthropic, crowned as its “preferred” cloud provider. The juxtaposition of “preferred” versus “primary” leaves room for speculation on the true hierarchy of these affiliations and the underlying strategic plays.
Smaller cloud players are taking a flexible, BYOM (Bring Your Own Model) approach, emphasising customisation and partnerships over proprietary models.
The major cloud platforms are likely jockeying for exclusive LLM access to capture the enormous compute demands needed to train and run these models. LLM companies will be among the biggest cloud compute customers. However, in my view the prize is much bigger than just the training runs.
We can expect more strategic investments and partnerships between cloud providers and LLM companies as this technology proliferates. Each platform is taking a different approach to balance proprietary IP with an open ecosystem
Additional Recommendations
Here are some recommendations that could potentially set cloud providers apart in the burgeoning landscape of foundational models:
Flexible LLM Integration Platforms
Creating universal interoperability standards for all proprietary LLMs would be hugely complex given technological constraints and competitive dynamics. A more pragmatic approach is building integration platforms that connect major LLMs using adapters and APIs. This provides flexibility without needing full standardisation.
Promote Trustworthy AI
Achieving complete transparency into the inner workings of complex LLMs is likely infeasible today given IP protections and technical barriers. However, providing transparency into key aspects like data practices, bias monitoring, and decision explanations fosters trust while supporting innovation.
Pioneer Federated Learning for LLMs
Continuous learning at scale requires immense investments in data engineering and instrumentation. Federated learning offers a more practical path by enabling decentralised learning across edges while preserving privacy and IP. This collaborative approach realises many benefits of continuous retraining at lower cost.
Become AI Facilitators, Not Just Infrastructure
While robust infrastructure is essential, cloud providers also need to provide high-level services that simplify AI development. This facilitates adoption by handling complexity on behalf of developers through auto-generated code, MLOps pipelines, collaboration tools, and more.
Offer Vertical AI Solutions, Not Just Horizontal Tools
Rather than generic LLMs, customers need optimised vertical AI solutions. Cloud providers can combine domain data, pre-built components, compliance guardrails and their infrastructure strengths to deliver tailored industry solutions.
🚀 Upcoming Free 1 Hour Webinar: Elevate Your Professional Game with AI!

Ready to take a deep dive into the world of Generative AI and how it can transform your enterprise or your professional work?
⏰ Act fast, the seats are filling up! ⏰
👉👉 [Register Now!] 👈👈
Engrossed in the Discourse? 🎯
If the discourse on the intelligence explosion, its disruptive tremors through proprietary AI, evolving tech stacks, and the new frontier of data pipelines ignites your curiosity - don't hold it back!
🔄 Share on Social: Enthralled by our exploration into the intelligence explosion and its ripple effects on enterprise AI? Click to share and tag peers who should be in the know!
📧 Forward It: Have colleagues delving into AI tech stack or navigating AI data pipeline dilemmas? They'll appreciate this deep dive - go ahead and forward it their way.
Your engagement propels us to probe deeper and challenge the norms. Together, let's chart the unexplored territories of AI and reshape the enterprise landscape!