
Issue #12 - Navigating Enterprise Transformation with Multimodal LLMs
Discovering the Power of Image and Video LLMs in 2024: A Comprehensive Guide for Enterprises on Harnessing AI for Enhanced Productivity and Strategic Intelligence


Happy 2024! I hope this message finds you well and that your holiday season was as enriching and rejuvenating.
As we step into this new year, full of promise and potential, I want to share with you some personal reflections that have shaped my outlook for the exciting times ahead.

Over the holidays, I found myself rediscovering the compelling science fiction of Iain M. Banks and his renowned Culture Series. Banks' vision of a utopian future and a post-scarcity world has always captivated my imagination and has sparked endless thoughts and ideas about the trajectory of our own civilisation. It's fascinating to ponder how AI, a central theme in the Culture series, is not just a technological force but a catalyst for societal and cultural transformation. The Culture is a hybrid society of humans, aliens, and a variety of AIs that coexist and contribute to the society's governance and culture. The series explores the implications of AI in terms of societal organisation, the distribution of power, and the nature of consciousness and individuality.
In addition to looking into the future, I delved into the past, exploring the history the early Persians through the captivating retelling by Lloyd Llewelyn-Jones. The Persians have been a highly misunderstood and under appreciated people, primarily because of the Western fascination with Greeks who painted the Persians in a discriminatory light. This book provided me with some very interesting insights into the arc of history, the construction and deconstruction of societies, governance structures and how these narratives resonate with our current technological era.

Both of these literary adventures - one looking far into the future, and the other far into the past - have given me abundant food for thought. They've shaped my perspective on where we are headed concerning AI, society, politics, and the future at large. I look forward to sharing more of these reflections with you in upcoming editions.
But first, in this edition of the newsletter, we turn our focus to the present and the near future of AI in the enterprise world.
We're delving deep into the capabilities of Multimodal Large Language Models (LLMs), specifically image-based Multimodal LLMs and their transformative impact on business operations. We'll also explore the upcoming capabilities of video LLMs - an advancement that enterprises need to take seriously. I'll guide you through how we can prepare for these changes, ensuring that our businesses are not only ready but are at the forefront of this technological revolution.
Introduction to Multimodal LLMs
Multimodal LLMs are an extension of LLMs that can process and generate outputs based on multiple types of input data, such as text, images, videos, and other modalities. This is a significant departure from traditional LLMs, which primarily deal with text data.
Multimodal LLMs are designed to handle the complexity and diversity of real-world data, which often comes in various forms and formats. For instance, in the context of healthcare, Multimodal LLMs can ingest a diversity of data modalities relevant to an individual's health status, such as their image scans, demographic, clinical features, and high-dimensional time-series data. In autonomous driving, Multimodal LLMs can merge vectorised numeric modalities of scenes with a pre-trained LLM to improve context understanding in driving situations.
Several examples of Multimodal LLMs have been developed to handle different types of data and tasks:
GPT-4V model: This is an extension of OpenAI's GPT-4 model, designed to handle multimodal inputs along with text instructions. GPT-4V has specifically shown promise in the healthcare domain interpreting medical images. For instance, in a study where it was used to answer medical licensing examination questions with images, GPT-4V achieved accuracies of 86.2%, 62.0%, and 73.1% on three different exams. Another study demonstrated that GPT-4V exhibits strong one-shot learning ability, generalisability, and natural language interpretability in various biomedical image classification tasks. However, it's important to note that while GPT-4V has shown proficiency in distinguishing between medical image modalities and anatomy, it faces significant challenges in disease diagnosis and generating comprehensive reports.
Gemini models: The Gemini family of models from Google, which includes Ultra, Pro, and Nano sizes, has advanced capabilities across image, audio, video, and text understanding. The Gemini Ultra model, in particular, has advanced the state of the art in 30 of 32 benchmarks, including achieving human-expert performance on the well-studied exam benchmark MMLU. A comparison between Gemini Pro and GPT-4V revealed that while both models exhibit comparable visual reasoning capabilities, they have different answering styles. GPT-4V tends to elaborate detailed explanations and intermediate steps, while Gemini prefers to output a direct and concise answer.
HeLM model: This model is used in healthcare, specifically for predicting asthma. It combines different types of data (like tabular data and spirogram data) to predict asthma with a high degree of accuracy. Think of it as a tool that can give an early warning for an asthma attack, potentially improving patient outcomes. HeLM model achieved an AUROC (Area Under the Receiver Operating Characteristic curve) of 0.75, a measure indicating its accuracy in asthma prediction.
V* model: This model is designed to process high-resolution images, focusing on visual details. It can analyse detailed images and provide insights based on what it sees. The model also introduced a new benchmark, V*Bench, to evaluate the performance of Multimodal LLMs in processing high-resolution images.
Video-ChatGPT model: This model is capable of understanding and generating human-like conversations about videos. It's like having a virtual assistant that can watch a video and then have a detailed conversation about it. The model was trained using a new dataset of 100,000 video-instruction pairs and a quantitative evaluation framework was developed to assess its performance
Driving with LLMs model: This model is used in the field of autonomous driving. It can interpret driving scenarios, answer questions, and make decisions, much like a human driver would. The model was tested in a simulated driving environment and showed impressive ability to reason and solve complex scenarios.
ChartLlama: This model is designed for interpreting chart figures. It outperforms all prior methods in ChartQA, Chart-to-text, and Chart-extraction evaluation benchmarks.
LiDAR-LLM: Designed for 3D LiDAR understanding, it reformulates 3D outdoor scene cognition as a language modelling problem and shows favourable capabilities in various instructions regarding 3D scenes.
Multimodal LLM Tools
The good news is that multimodal LLM capabilities are available to use for free via Microsoft Copilot and Google Bard, and if its something you are keen to try its the best way to get started. There are paid versions also available via ChatGPT Plus and Perplexity but in terms of capabilities there is not much difference between the paid and free versions. Below is a list if chat-based LLM tools that have multimodal LLM capabilities for image-based inputs.
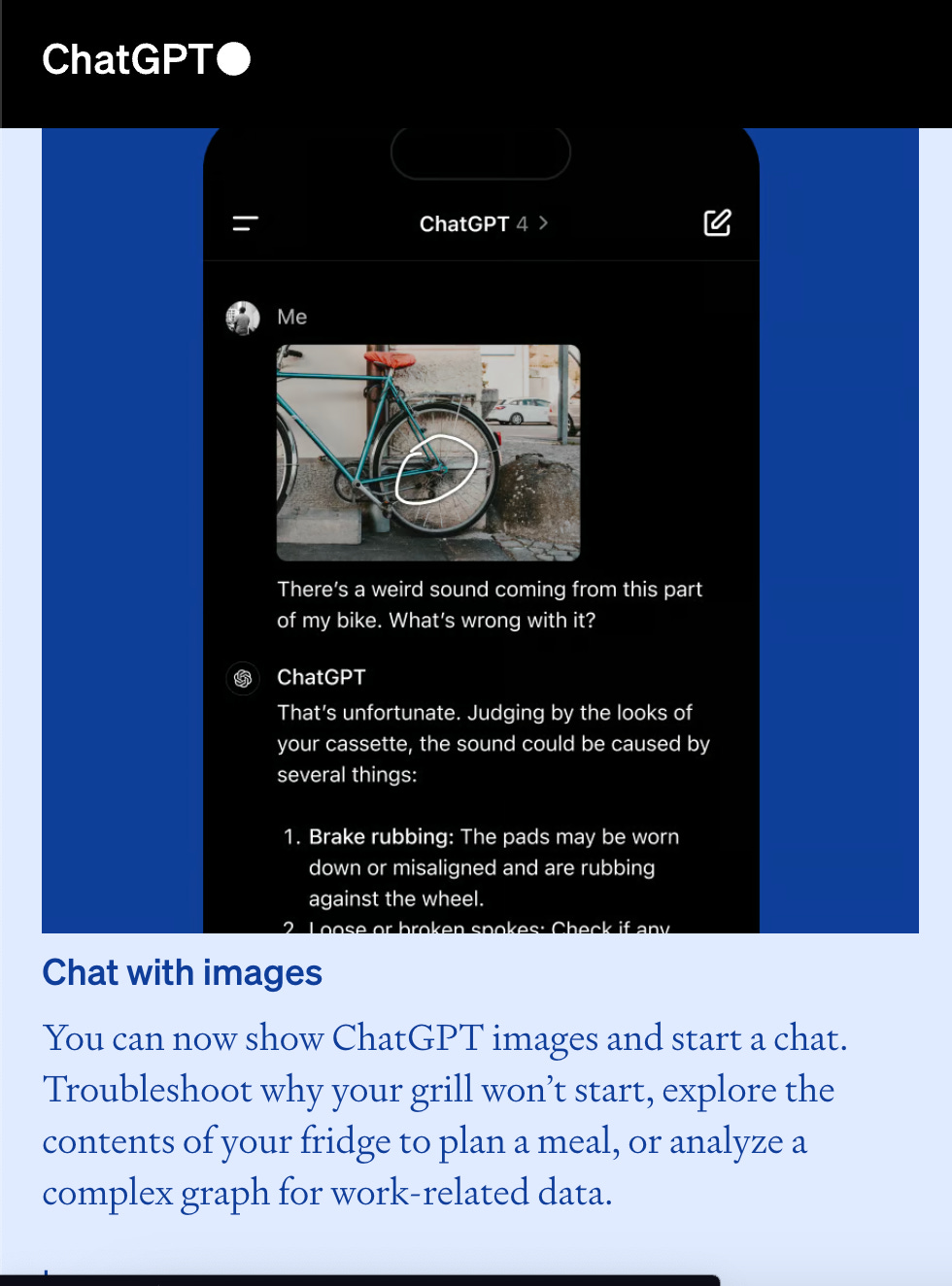
ChatGPT Plus (Paid): ChatGPT Plus, provides access to the advanced GPT-4 model, which includes multimodal capabilities. ChatGPT Plus can process both text and images, allowing users to input images and receive relevant textual responses. OpenAI has released API access to its GPT-4 Turbo Vision model via its API, but there is no indication whether ChatGPT Plus users get access to this model for their multimodal queries. ChatGPT Plus users can also use audio inputs in addition to image inputs making it a truly multimodal LLM. Another feature that ChatGPT Plus provides is the ability to use image as an input and have DALLE-3 create a similar image or something inspired by the image.
Perplexity Pro (Paid): The main advantage of Perplexity is the ability to combine search with multimodal inputs and outputs and the ability to access multiple AI models. The Pro version of Perplexity AI, which is a paid service, offers access to advanced AI models such as GPT-4, Claude-2, Gemini Pro and others. GPT-4 and Gemini Pro are known for their multimodal capabilities which can be accessed through the tool. The Pro version allows for unlimited attachments of images or files. Perplexity also offers a free version with a limited amount of image uploads and models.

Google Bard with Gemini Pro (Free): Bard, powered by Google's Gemini Pro, is a conversational AI service that offers sophisticated multimodal reasoning capabilities. While Bard initially had limited multimodal functions, the integration of Gemini Pro has significantly enhanced its abilities. Gemini Pro is designed to handle various data types, including text, images, audio, and video, allowing Bard to perform tasks like visual understanding and answering questions about images.
Microsoft Copilot (Free): Microsoft Copilot is the rebranded Microsoft Bard Chat that uses GPT-4 as the underlying LLM and is built as a wrapper around the LLM. In its current version, Copilot provides the ability to attach images and use GPT-4 as an image-based multimodal LLM. As per new enhancements planned for 2024, Copliot will get access to GPT-4 Turbo which has enhanced multimodal capabilities. Copilot will also combine GPT-4 vision with Bing image search and web search data to deliver better image understanding of queries, which is termed as ‘multimodal with search grounding’.
Empowering Enterprises with Image-Based Multimodal LLMs

Lets explore how multimodal visual LLMs can be integrated into daily business operations and strategic planning.
First we look at practical applications that enhance everyday productivity. Then, we shift our focus to the strategic implications of leveraging LLMs for long-term enterprise intelligence.
Streamlining Daily Productivity with Practical Applications
Meeting and Event Documentation: In the realm of business, meetings and events are pivotal. However, the key takeaways and actions often get lost in the shuffle of day-to-day activities. Here's where image-based Multimodal LLMs come into play. By capturing images of whiteboard notes or presentation slides, these advanced AI systems can transform visual content into organised, accessible summaries. This not only ensures that critical information is retained but also facilitates efficient follow-up actions.
Document Management and Networking: Handling a multitude of business documents and networking contacts is a common yet cumbersome task. Image-based LLMs offer a solution by enabling the quick extraction of essential information from images of documents and business cards. This capability streamlines data organisation, making it easier to access and utilise information effectively, thereby enhancing both internal processes and external networking efforts.
Financial Administration: Managing expenses and finances is an integral part of any business operation. With the aid of image-based LLMs, the process of categorising expenses becomes more straightforward. Simply upload images of receipts or invoices, and the system categorises and compiles them into comprehensive reports. This not only saves valuable time but also increases the accuracy of financial reporting, a crucial aspect of sound financial management.
Despite many organisations using OCR-based expense management systems, its worthwhile to test image-based Multimodal LLMs as their accuracy and ease of use far outweighs existing OCR based systems.
Data Analysis and Decision Support: In today’s data-driven environment, making sense of complex data visualisations is crucial for informed decision-making. Image-based LLMs assist by interpreting graphs and charts from business reports or presentations. When these images are uploaded, the LLMs can provide in-depth analyses and insights, aiding executives and managers in making more informed decisions swiftly, especially during high-stakes meetings.
Legal Document Analysis: Image-based Multimodal LLMs can revolutionise this aspect, not by replacing legal teams, but by augmenting their capabilities. These AI tools can expedite the initial stages of legal document analysis, efficiently scanning and interpreting images of contracts and compliance documents. They can identify key terms, obligations, and potential liabilities, which is especially beneficial in scenarios like due diligence, mergers, acquisitions, and routine contract management. By automating the initial review process, legal professionals can focus on more complex and nuanced aspects of legal work.
Enhancing Strategic Enterprise Intelligence
As enterprises navigate the complex landscape of modern business, the potential of visual Multimodal LLMs to revolutionise strategic intelligence is becoming increasingly apparent. These AI systems, adept at interpreting and analysing visual data, offer transformative capabilities for a range of strategic applications.
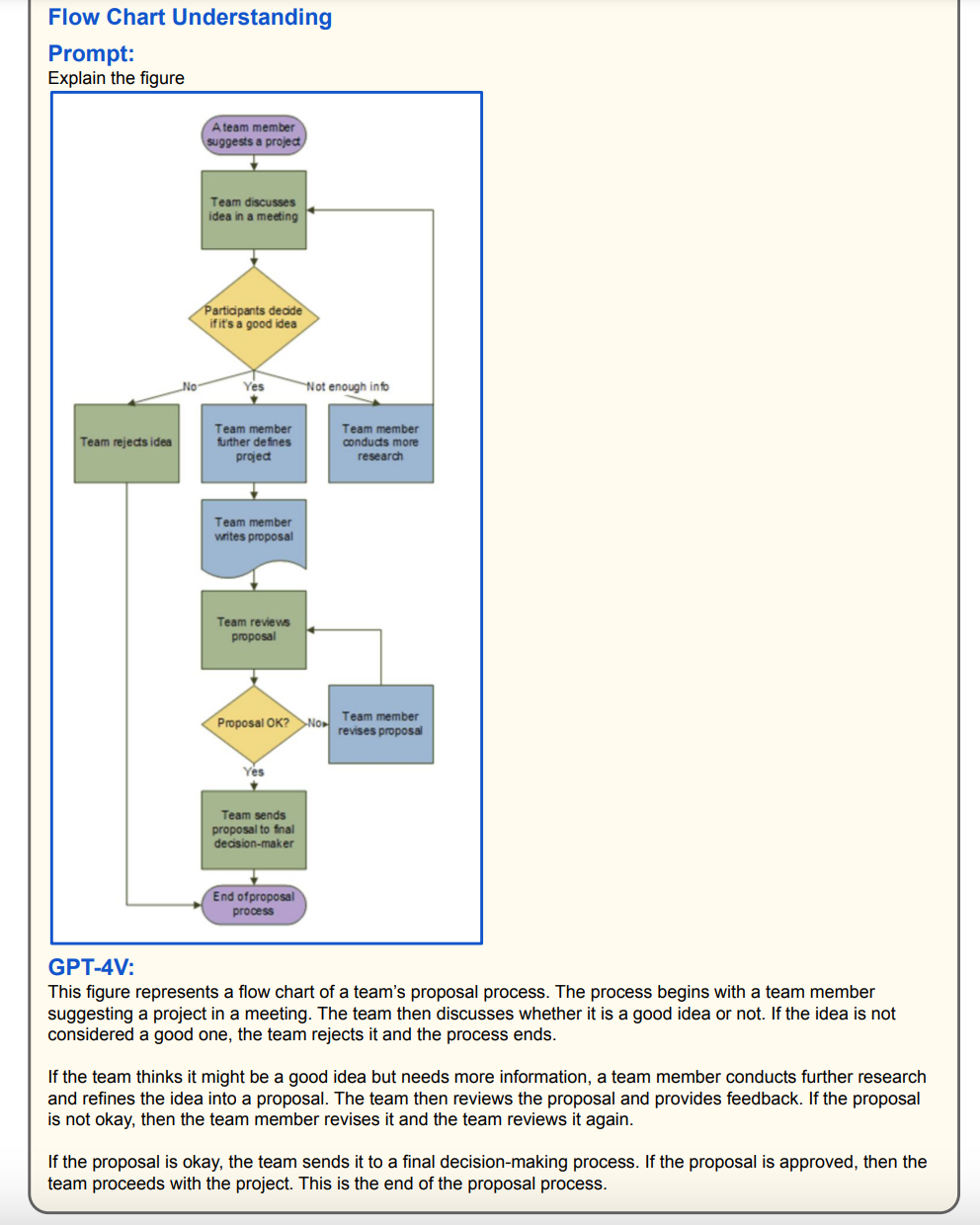
Strategic Organisational Development: Visual Multimodal LLMs can be utilised to dissect organisational and process flowcharts, enabling businesses to uncover and address hidden inefficiencies. By meticulously analysing these charts, LLMs can pinpoint specific areas where processes can be streamlined or restructured, offering recommendations to enhance organisational effectiveness. This analysis can lead to significant improvements in workflow, resource allocation, and overall operational efficiency.
Comprehensive Infrastructure Analysis: In infrastructure planning and development, LLMs can offer invaluable insights by examining blueprints and design plans. This deep analysis covers critical aspects such as space utilisation, structural design efficiency, and future scalability. Enterprises can leverage these insights for long-term infrastructure planning, ensuring that their physical spaces and structures are optimally aligned with their evolving business needs and goals.
Advanced Asset Management: LLMs can play a critical role in asset management by conducting thorough assessments of physical assets like vehicle fleets and manufacturing layouts. By analysing images of these assets, LLMs can assess their condition, usage patterns, and maintenance requirements, thereby aiding in the development of strategic maintenance schedules and optimisation plans. This approach not only helps in extending the life of these assets but also ensures their efficient utilisation, contributing to cost savings and operational excellence.
Strategic Location Intelligence: For businesses considering expansion, LLMs can be a powerful tool for evaluating potential new site locations. By analysing images of locations, these models can assess factors such as geographical advantages, available infrastructure, and logistical challenges. This comprehensive analysis assists enterprises in making informed decisions about site selection, ensuring that new locations are well-suited to their strategic objectives and operational requirements.
Integrated Supply Chain Strategy: LLMs can significantly enhance supply chain management by providing a detailed analysis of visual supply chain networks. Through this analysis, businesses can identify bottlenecks, potential risks, and areas for efficiency improvement. By implementing the suggested strategies, enterprises can develop more resilient and efficient supply chains, better equipped to handle the dynamic demands of modern commerce.
Innovative Product and Market Development: In product development, LLMs can be utilised to gain deeper insights into product design and market alignment. By analysing images of product prototypes, these models can offer feedback on design aspects, potential market fit, and areas for improvement. This feature is particularly beneficial for businesses looking to innovate and stay ahead of market trends, ensuring that their products resonate with consumer needs and preferences.
Retail and Space Utilisation Enhancement: In the retail sector, LLMs can optimise store layouts and space utilisation based on an analysis of visual data. By aligning store design with observed consumer behaviour patterns and business goals, these AI tools can enhance the overall shopping experience, potentially leading to increased customer satisfaction and sales.
Harnessing Video LLMs for Process Automation
The evolution of enterprise AI is poised for a significant leap with the introduction of video-based Multimodal LLMs, particularly in the realm of process automation. This advancement differs markedly from image-based Multimodal LLMs, primarily in its ability to interpret and learn from dynamic, sequential video data - a feature that is crucial for comprehensively understanding and optimising complex workflows.
We have covered pioneering companies like Induced AI in the past, that are utilising video LLMs for process analysis. Induced AI's methodology involves capturing video screen grabs of employees' web-based workflows. These recordings serve as a dynamic visual repository, providing a sequential, in-depth view of various tasks and operations undertaken within the enterprise.
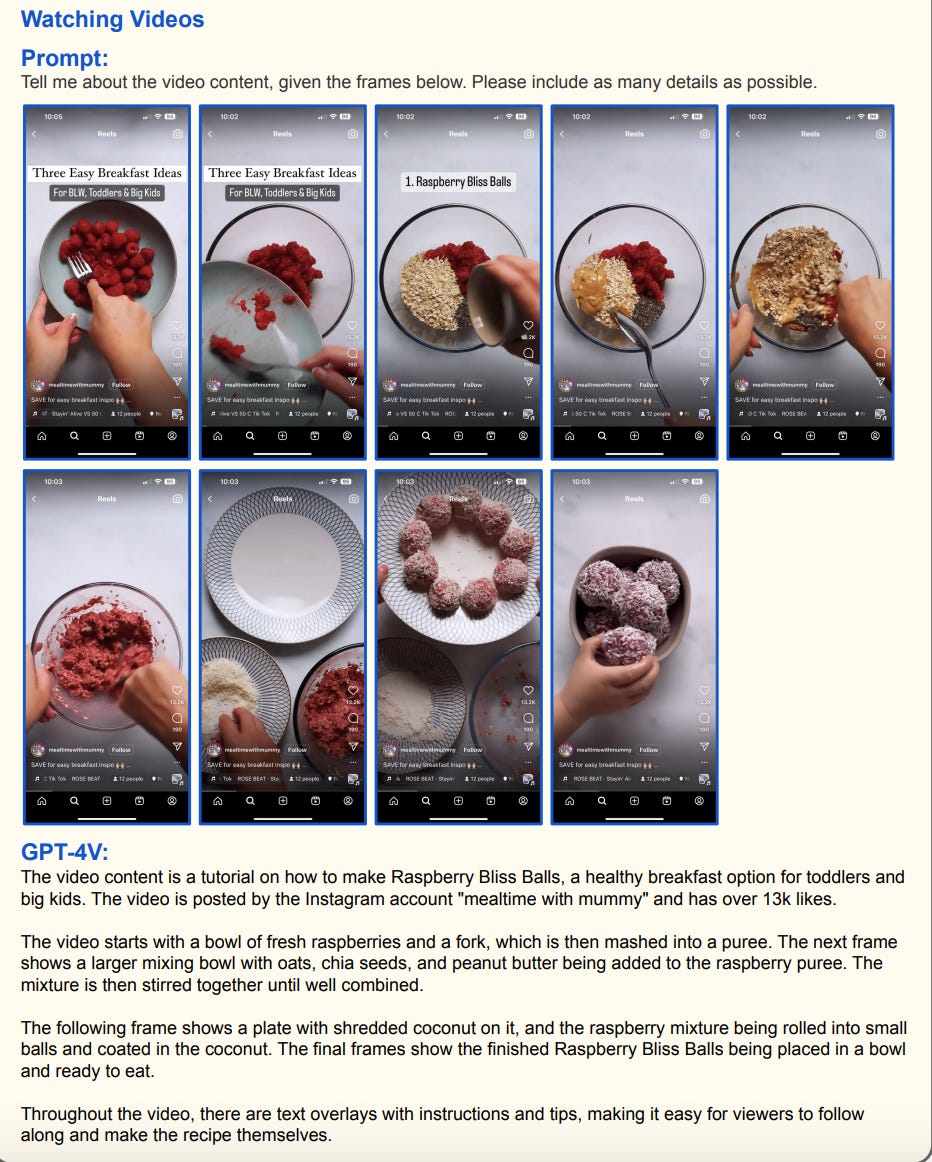
The significance of this method lies in its capability to capture the nuances of workflows in a way that static images cannot. While image-based LLMs are adept at analysing single-frame visual data, video LLMs excel in interpreting a series of actions over time, providing a richer context and a clearer understanding of process flows. This temporal dimension is vital for identifying not just what tasks are being performed, but also how they are being executed, revealing inefficiencies and potential areas for automation.
Video LLMs are still in beta phase and have yet to be released publicly in a chat-style interface, but expect 2024 to see a lot of activity in this space both from specialised startups and the LLM leaders like OpenAI, Microsoft, Google and others.
So, how can enterprises start to prepare of video LLMs?
Here are some steps that enterprises can start to implement in preparation for video LLMs.
Documenting and Analysing Workflows
The process begins with employees recording their routine digital activities. These recordings provide a real-time, unfiltered view of the current operational procedures, serving as a baseline for analysis. By documenting these workflows, video LLMs can later dissect and understand the intricacies of each task, from simple repetitive actions to more complex, multi-step processes.
Differentiating Manual and Automated Tasks
A critical aspect of using video LLMs is their ability to help distinguish between tasks that can be automated and those that require human oversight. By analysing the screen captures, the LLMs can pinpoint operations that are repetitive and rule-based - ideal candidates for automation - and separate them from tasks that need human judgment, creativity, or contextual decision-making.
Future Potential with Video LLMs
As video LLM technology becomes more prevalent, it is anticipated that these AI systems will not only analyse existing recordings but also actively suggest process improvements and automation strategies. This predictive capability will be instrumental in transforming enterprise workflows, making them more efficient, cost-effective, and adaptable to changing business needs.
In summary, the use of video LLMs in process automation represents a significant shift in how enterprises can understand and optimise their workflows. By leveraging the dynamic analysis capabilities of these AI models, businesses can embark on a more informed and strategic path towards automation, enhancing productivity and operational excellence.
For anyone interested in further reading on Mutimodal LLMs and their applications below is a list of papers that are recommended.